Query a 3rd-Party DBMS
If you have chosen to store your VTScada data in a 3rd-party database management system, be aware that Historian redundancy may create multiple copies of data. This is done to ensure reliability, but can mean that retrieving data is not a simple matter of collecting sets of timestamps and values for a tag. In the case of conflicts, refer to the value in the arbitration column. As a general guide, you are advised to use VTScada's data retrieval tools including SQL Queries and SQLQuery rather than query a 3rd-party database directly.
If writing your own queries, the steps vary depending on whether you have chosen to store data in a single table for each type of tag, or to store each tag's data in its own table.
ODBC storage type
If you have configured your Historian tags with the storage type, ODBC, then tag data will be stored into separate tables for each tag. For example:
systemhistorian_rd29drhfxy7k8ye2o92s00000615zf
systemhistorian_rd29drhfxy7k8yenstx000000815zf
etc.
Assume that you have a tag named "\Station 1\ModDriver\Pump 1\Flow" and want to retrieve its logged data directly from your ODBC database. Using a series of queries, you can find this tag as follows:
SELECT * FROM systemhistorian_friendlytagnamelookup WHERE friendlyname = 'Station 1\\ModDriver\\Pump 1\\Flow';
+-----------------------------------+---------------------------------------------+-------------------------------------------------+ | friendlyname | uniqueID | tablename | +---------------------------------------------+---------------------------------------------+---------------------------------------+ | Station 1\ModDriver\Pump 1\Flow | (rd29d~r}h\fxy7k!8@ye\#ssm(o~p#r\g#_t_m^2qz | SystemHistorian_rd29drhfxy7k8yessmop00000a15zfs | +-----------------------------------+---------------------------------------------+-------------------------------------------------+
This tells us which table holds the tag's data. You can now query that table:
SELECT Timestamp, value from SystemHistorian_rd29drhfxy7k8yessmop00000a15zfs WHERE Timestamp < '2020-04-07 16:25:50' AND Timestamp >= '2020-04-07 14:25:50';
It is not possible to combine these two queries into one with a JOIN operation because we do not know the name of the table that holds the tag's data until after performing the first query. For this reason, the storage type, ODBCSingleTable is generally preferred.
ODBCSingleTable storage type
If you have configured your Historian tags with the storage type, ODBCSingleTable, then tag data will be collected into tables according to their type. For example:
systemhistorian_numerics
systemhistorian_drivers
etc.
For clarity on data storage, the following examples use a single query for each step of the process of identifying where to look for a tag. In practice, a JOIN operation is recommended, both to simplify data retrieval into a single query and to avoid the need to escape backslash characters in 'uniqueID' values.
Assume that you have a tag named "\Station 1\ModDriver\Pump 1\Flow" and want to retrieve its logged data directly from your ODBC database. Using a series of queries, you can find this tag as follows:
SELECT * FROM systemhistorian_friendlytagnamelookup WHERE friendlyname = 'Station 1\\ModDriver\\Pump 1\\Flow';
+-----------------------------------+---------------------------------------------+--------------------------+ | friendlyname | uniqueID | tablename | +-----------------------------------+---------------------------------------------+--------------------------+ | Station 1\ModDriver\Pump 1\Flow | (rd29d~r}h\fxy7k!8@ye\#ssm(o~p#r\g#_t_m^2qz | systemhistorian_Numerics | +-----------------------------------+---------------------------------------------+--------------------------+
This tells us which table holds the information and what the tag's unique ID looks like to the database.
Before querying that table, note two details:
- The uniqueID value contains backslash characters. If performing multiple queries as shown, you may need to configure your database to allow these to be treated as simple characters rather than as escape characters. That step is not required if using a JOIN operation, as shown in the example at the end of this topic.
- systemhistorian_Numerics doesn't have a uniqueID column, identifying the tags. Instead, tags are identified using an integer ID, stored in the column TagID. To discover the TagID for our Flow tag, we must query systemhistorian_tagidentifierlookup as follows, using the UniqueID from the previous query.
SELECT * FROM systemhistorian_tagidentifierlookup WHERE tagname = '(rd29d~r}h\fxy7k!8@ye\#ssm(o~p#r\g#_t_m^2qz';
+----+---------------------------------------------+----------------------------+ | id | tagname | tagidentifier | +----+---------------------------------------------+----------------------------+ | 10 | (rd29d~r}h\fxy7k!8@ye\#ssm(o~p#r\g#_t_m^2qz | rd29drhfxy7k8yessmop00000a | +----+---------------------------------------------+----------------------------+
This tells us that the tag's id value is 10. Finally, we can query for the stored flow values:
SELECT Timestamp, Value FROM systemhistorian_numerics WHERE TagID = 10 AND Timestamp < '2020-04-07 16:25:50' AND Timestamp >= '2020-04-07 14:25:50';
+---------------------+-------+ | Timestamp | Value | +---------------------+-------+ | 2020-04-07 14:27:09 | 10 | | 2020-04-07 14:27:11 | 325 | | 2020-04-07 14:27:13 | 482 | ...
Merging the three previous queries into a single query with JOIN operations will avoid the need to handle backslash characters in the tag's Unique ID / tagname. For example:
SELECT Timestamp, Value FROM systemhistorian_numerics INNER JOIN systemhistorian_tagidentifierlookup ON TagID = id INNER JOIN systemhistorian_friendlytagnamelookup ON tagname = uniqueID WHERE friendlyname = 'Station 1\\ModDriver\\Pump 1\\Flow' AND Timestamp < '2020-04-07 16:25:50' AND Timestamp >= '2020-04-07 14:25:50';
Historian Redundancy and Edited Values
As noted elsewhere (Historian Data Storage), VTScada may record redundant values to ensure data integrity in a multi-server environment. It is also possible for authorized users to Edit Data, although this means adding new values with matching timestamps rather than changing values.
To deal with either situation, use the Arbitration column. Larger values mean a later addition. When using VTScada's built-in tools to query history, if two records with matching timestamps are found, the one with the larger arbitration value is chosen automatically.
For example, consider the following result set:
+---------------------+---------------------+-------------+-------+ | Timestamp | VTS_Historian_TS | Arbitration | value | +---------------------+---------------------+-------------+-------+ | 2020-04-08 11:57:49 | 1586347068836000000 | 1586347068 | 629 | | 2020-04-08 11:57:51 | 1586347070839000064 | 1586347070 | 619 | | 2020-04-08 11:57:53 | 1586347072842000128 | 1586347072 | 0 | | 2020-04-08 11:57:49 | 1586347068836000000 | 1586349734 | 700 | +---------------------+---------------------+-------------+-------+
The first and last records in this sample have identical timestamps. Only the Arbitration column tells us that the last record (700) was added later. Referring to the grid view of the VTScada Historical Data Viewer (raw data mode) we can see the history of this change:
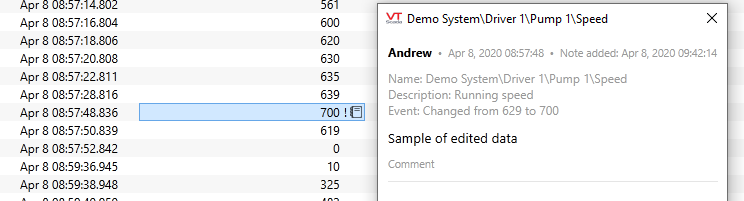
(Stored timestamps are in UTC. The image from the Historical Data Viewer shows timestamps adjusted to Atlantic Daylight Time.)
